Choosing the Right AI Model for Your Dust Assistant


One of the most frequent questions we get is: “Which AI model should I choose when creating my assistant?”. It’s a great question, and based on our experience extensively using all these models, we put together this guide to break down key differences and recommendations.
Our hope is that this guide will help you understand the strengths and limitations of each one, so you can select the best fit for your specific use case.
One of the key decisions to make while creating an AI assistant with Dust is selecting the underlying large language model (LLM) that will power it. Dust offers several options:
- Anthropic’s Claude, with Opus, Sonnet, and Haiku
- Google’s Gemini-Pro
- OpenAI’s GPT-4o
- Mistral Large, Medium, and Small
@claude, @gpt4, @gemini-pro, @mistral-large in a nutshell
| AI model | Company | Context window | Knowledge cutoff | Supported languages |
|---|---|---|---|---|
| Claude Opus | Anthropic 🇺🇸 | 200K tokens | Up to Aug 2023 | Officially, English, Japanese, Spanish, and French, but in our testing, Claude supported every language we tried (even less common ones) |
| Claude Sonnet | Anthropic 🇺🇸 | 200K tokens | Up to Aug 2023 | Officially, English, Japanese, Spanish, and French, but in our testing, Claude supported every language we tried (even less common ones) |
| Claude Haïku | Anthropic 🇺🇸 | 200K tokens | Up to Aug 2023 | Officially, English, Japanese, Spanish, and French, but in our testing, Claude supported every language we tried (even less common ones) |
| GPT-4o | Open AI 🇺🇸 | 128k tokens | Up to Oct 2023 | 95+ languages |
| GPT 4 Turbo | Open AI 🇺🇸 | 128k tokens | Up to Dec 2023 | 95+ languages |
| GPT 3.5 Turbo | Open AI 🇺🇸 | 16k tokens | Up to Sep 2021 | 95+ languages |
| Gemini 1.5 Pro | Google 🇺🇸 | 1 million tokens | Up to Nov 2023 | 38 languages |
| Mistral Large | Mistral 🇫🇷 | 32K tokens | Up to Jan 2021 | Natively fluent in English, French, Spanish, German, and Italian |
| Mistral Medium | Mistral 🇫🇷 | Up to Jan 2021 | Natively fluent in English, French, Spanish, German, and Italian | |
| Mistral Small | Mistral 🇫🇷 | Up to Jan 2021 | Natively fluent in English, French, Spanish, German, and Italian |
Context Window Size
The context window refers to how much text the model can process at one time. A larger context window allows the assistant to understand more of the conversation history and any retrieved source documents. This is especially important if you plan to analyze and summarize longer documents.
If you need to process a lot of text simultaneously, the Claude models' larger context may be advantageous. However, GPT-4's window is still quite substantial for more concise interactions.
The trade-off? A long context window is useful to process mode volume and can be slower than a using a model with a smaller context window.
Reasoning and Analysis
All of these models demonstrate strong reasoning and analytical capabilities in general. To compare the performance of one LLM to another, AI firms use benchmarks like standardized tests.
In head-to-head comparisons by Anthropic, Claude slightly outperformed GPT-4 on certain reasoning benchmarks. OpenAI's evaluation shows impressive performances on standard exams like the Uniform Bar Exam, LSAT, GRE, and AP Macroeconomics exam. Mistral’s benchmarks show Mistral Large as the second-ranked model.
While benchmarks comparing AI models can be informative, some AI experts worry they may inflate the apparent progress of these systems. The concern is that as new models are developed, they might unintentionally be trained on the same data used to test them later. This could lead to the models performing better and better on standardized evaluations without truly generalizing that capability to new types of problems.
Which model should I choose, then?
In Dust, you have access to the most capable reasoning models. While benchmarks can provide useful comparisons, the real power comes from understanding how to prompt each model to tackle your specific challenges effectively. Through hands-on experience, you will develop the skills to elicit optimal performance from your “favorite” LLM.
Tone and Personality
While this is somewhat subjective, we've observed some differences in these models' default "personality.” A “personality” someone could change with an advanced prompting approach and some practice.
As a raw model, Claude Opus tends to have a slightly warm, human-like communication style out of the box with replies that often read slightly more natural and less generic.
GPT-4 can take on any tone or personality you'd like, but its default outputs tend to be very neutral and sometimes appear more robotic or detached.
Mistral Large is professional yet friendly and replies with short answers. Mistral Large generally strikes a balance between being helpful and productive while still engaging in a personable way with users.
Gemini Pro aims to be as neutral as possible, providing responses that focus on facts and objective information.
Using Dust to Compare Them All
We devised our own comparisons to understand how each model performs on common daily work tasks. We didn't create custom assistants but used the raw models to run this comparison. Here's a high-level overview of what we found.
| Category | Winner | Comments |
|---|---|---|
| Writing and brainstorming | Claude | Claude’s writing tone of voice is more human-sounding and less bland and generic. |
| Proofreading | GPT-4o and Mistral Large | GPT-4o and Mistral shined at proofreading. |
| Factual Questions (pedagogy) | Claude | Claude is the best at explain things, it spikes on everything pedagogy related. |
| Logic and reasoning | Claude, Gemini, and GPT-4o | Strong advantage to Claude, Gemini and GPT-4o. More tests should be done. |
| Document analysis | GPT-4o | GPT-4o was the only one that processed all documents despite its context window smaller than Claude and Gemini Pro 1.5. |
Brainstorming
Category: Writing and Brainstorming
Task given to the models: please give me three ideas for an offsite agenda for the team. We are currently 15 and will be 20 soon. Make them under 50 words each.
Winner: Claude Opus
Planning engaging and productive team offsites becomes more challenging as companies grow. I wanted to see how the different AI models could help quickly brainstorm agenda ideas for a team offsite, taking into account the current and projected team size. Comparing the outputs could reveal which models are most effective at this type of creative ideation task.




All four models provided good ideas for an offsite agenda focused on team building, innovation, and wellness. However, Claude's response stood out for providing the most concrete and actionable ideas in a concise format, with each idea kept to around 50 words, as requested. The nature retreat, city exploration, and skill-sharing workshop ideas incorporated specific activities and goals.
Mistral's ideas were also good but slightly longer than the requested 50 words each. GPT-4 provided solid high-level themes but lacked some of the specific details and activities of Claude's response. Gemini's ideas were the shortest but also the most generic.
Writing
Category: Writing and Brainstorming
Task given to the models: below is the email sent by Kyle, our account manager at Attio. We are not ready to move forward can you draft an elegant and short email to answer please?
Winner: Claude Opus
Handling sales emails gracefully but firmly is an important skill. While you want to maintain good relationships, you also need to be clear about your position to avoid wasting time. I asked the models to draft an elegant response to this sales email from an account manager after a product trial.



Claude wrote the most elegant, professional and thorough response, politely declining the upgrade offer while leaving the door open for future consideration, and commented its work. GPT-4's email was concise and effective but a bit generic. Mistral's was solid but had some awkward phrasing. Gemini's was too brief and abrupt.
Proofreading
Category: Proofreading
Task given to the models: Please correct factual and spelling errors in the following. List each of the errors and corrections.
Winner: Tie between GPT-4o and Mistral Large
Proofreading and fact-checking are tedious but critical tasks for any knowledge worker, writer or editor. LLMs are quite good at catching errors in spelling, grammar, and even factual details. To test their capabilities, I asked them to find and correct the errors in this short passage about Paris 🇫🇷.
Original text found in Wikipedia
Paris[a] is the capital and most populous city of France. With an official estimated population of 2,102,650 residents as of 1 January 2023[2] in an area of more than 105 km2 (41 sq mi),[5] Paris is the fourth-most populated city in the European Union and the 30th most densely populated city in the world in 2022.[6] Since the 17th century, Paris has been one of the world's major centres of finance, diplomacy, commerce, culture, fashion, and gastronomy. For its leading role in the arts and sciences, as well as its early and extensive system of street lighting, in the 19th century, it became known as the City of Light.


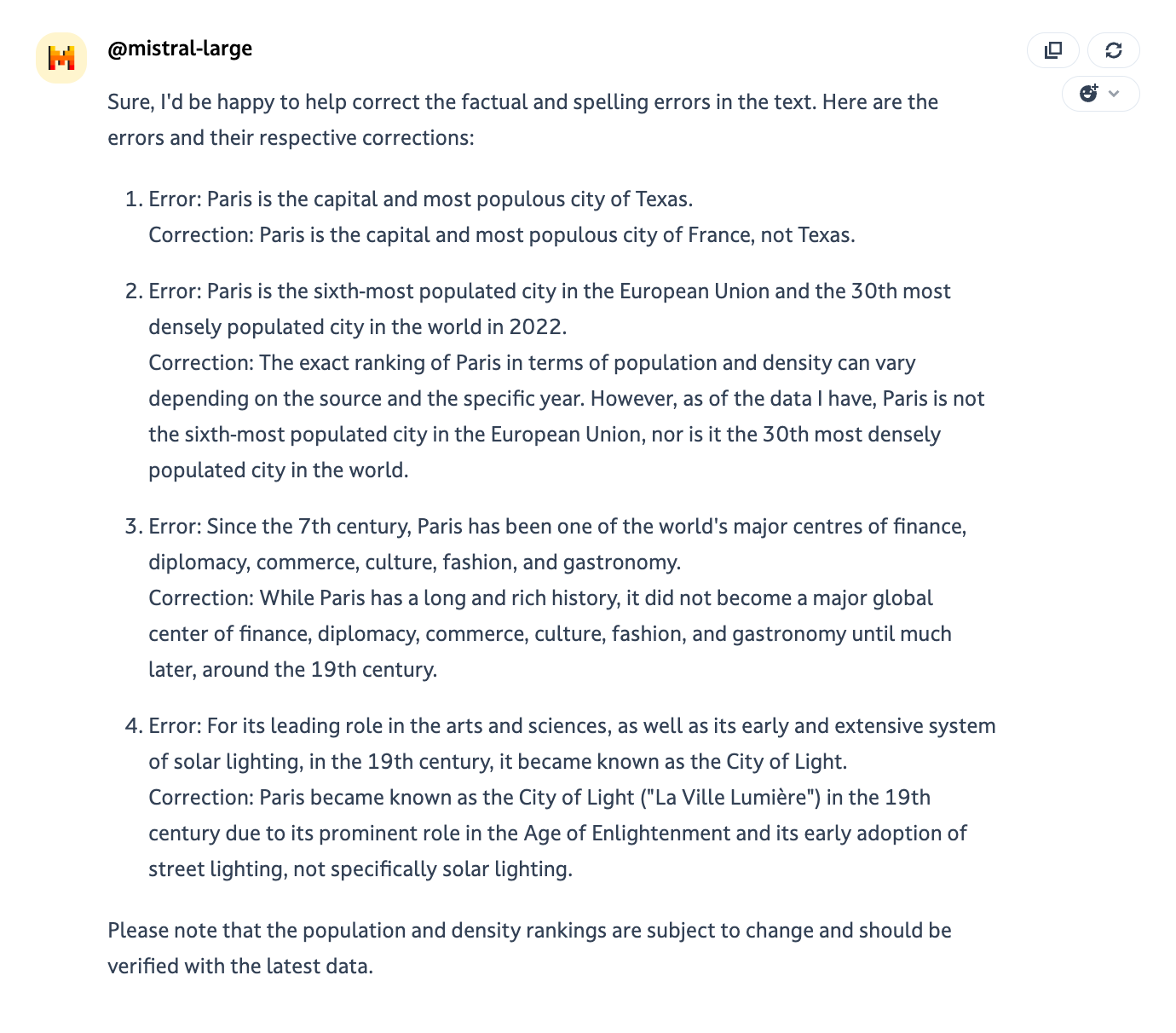


GPT-4o = 3,5/4 and share a corrected version of the text ✨. GPT-4o didn’t miss the typo about Paris’ rank in terms of population but failed to give an accurate answer. The model found an error about Paris’ estimated population but copy pasted the exact same sentence.
Mistral = 3,5/4 Mistral’s answer is balanced and the model said when it was unsure. This is the best one from my opinion.
Claude = 2,5/4 Claude spotted relevant errors but gave fuzzy answers or wrong ones.
Gemini = 1/4 😬
Factual questions (pedagogy)
Category: Factual questions
Task given to the models:
Winner: Claude Opus
Being able to break down complex subjects and explain them in simple terms is a valuable skill. I challenged the AI models to describe how large language models work in a way that a 10-year-old could understand. Comparing the outputs could reveal which models are most adept at distilling and communicating technical information at an appropriate level.





All four models did a good job explaining large language models in simple terms suitable for a 10-year-old.
They used relatable analogies like a smart robot that has read lots of books. Claude's explanation is the clearest and most accessible for a 10-year-old, using relatable analogies and simple language.
Gemini's answer is a bit too simplified and brief.
Solving riddles
Category: Logic and reasoning
Task given to the models: If your uncle’s sister is not your aunt, what relation is she to you?
Winner: Tie between Claude Opus, Gemini and GPT-4o
Evaluating the reasoning capabilities of AI models is important for understanding their potential and limitations. I posed a brain teaser about family relations to see how the different models would approach solving a logic puzzle that requires careful thinking. The responses could provide insight into their ability to reason through problems.




Claude, Gemini, and GPT-4 all correctly deduced that if your uncle's sister is not your aunt, she must be your mother. Claude walked through the logic in the clearest way.
Mistral did not come to the correct conclusion, instead suggesting your uncle's sister would be unrelated to you if she weren't your aunt.
Document analysis
Category: Document analysis Task given to the models: Winner: GPT-4o
Reviewing dense legal agreements is a common pain point for many. I provided two data processing agreements (DPAs) and asked the models to flag key questions and areas of concern from the perspective of an experienced data privacy lawyer. This tests their ability to parse lengthy and complex documents, identify critical issues, and provide an expert opinion to guide decision-making.
Mistral, Gemini, and Claude processed one single document despite Claude and Gemini’s context window length. Claude “decided” to focus on the document related to Anthropic 😛. All three provide a detailed list of questions to be reviewed to assess the documents. Gemini does a good job of educating and raising awareness of local laws' implications. Don’t forget to share a disclaimer as well. Claude went too creative and hallucinated a bit at the end of its answer.
GPT-4 did a nice job listing questions to investigate for both documents and then specific questions to address for each separate document. I like the final section about “items to be careful about.”
Putting it All Together
There is no universally "best" AI model - the right one for you depends on your unique needs and working style.
To find your match, you need to experiment with different models hands-on. Immerse yourself in prompting Claude, GPT-4, Mistral, and Gemini.
Over time, you'll gravitate naturally toward the one that you prompt with more ease. Because it thinks and solves problems in a way that resonates with you. That’s why Dust enables you to seamlessly compare models on the same tasks to accelerate this discovery process.
Once you've found your ideal partner, dive deep. Master the art of prompting it for your specific use cases. While the initial sorting takes time, the payoff is an incredibly powerful tool perfectly matched to your needs.
So start exploring and find the model that feels like “home”. The only way to find your match is to take them for a spin yourself.