How We Taught AI Agents to Navigate Company Data Like a Filesystem
Dust built synthetic filesystems that map disparate data sources into navigable Unix-inspired structures. This transforms AI agents from search engines into knowledge workers capable of both structural exploration and semantic investigation across company data.

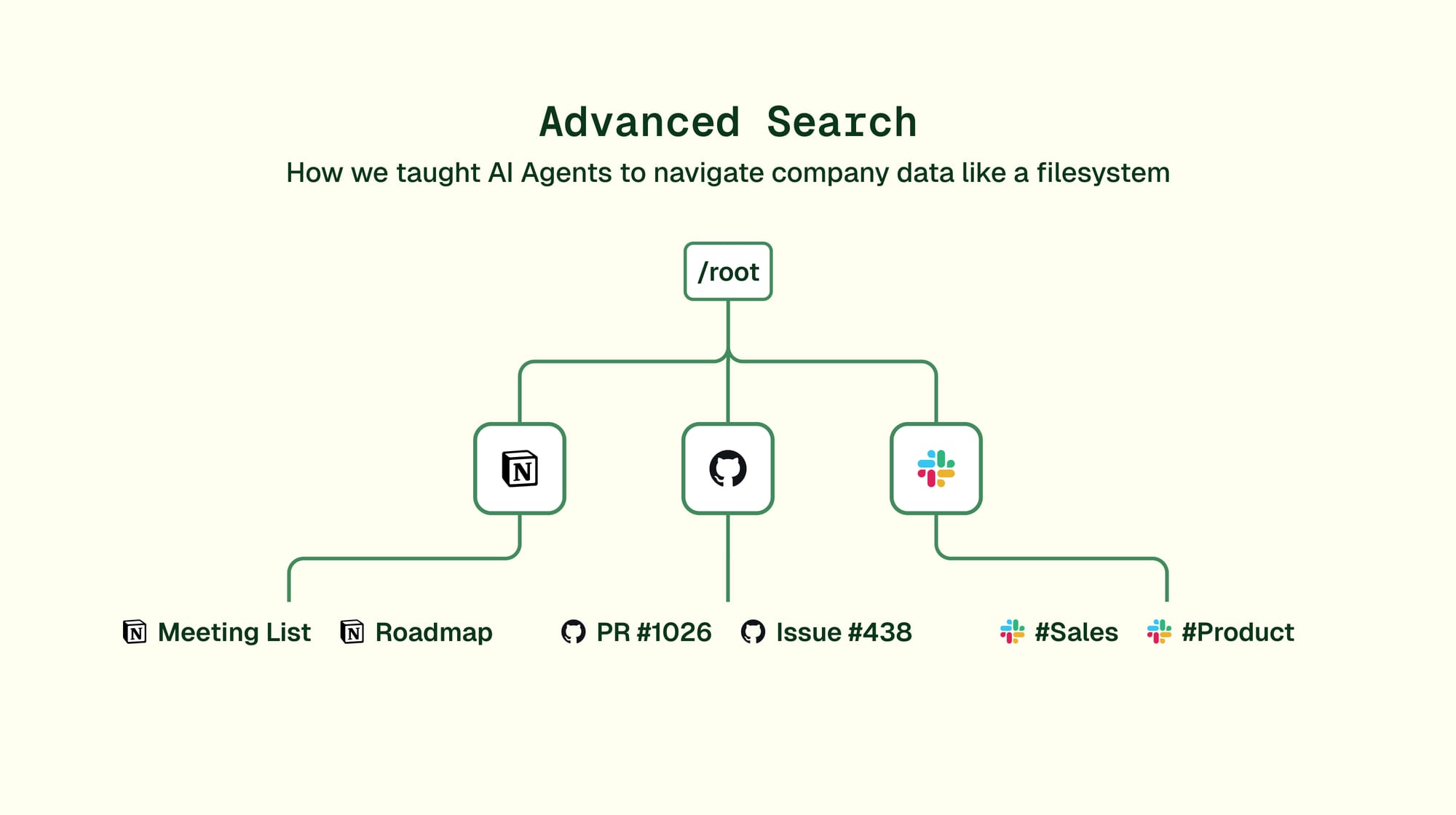
In April 2025, something kept showing up in our logs. Our AI agents were inventing their own syntax for searching content — file:front/src/some-file-name.tsx, path:/notion/engineering/weekly-updates. The agents were attempting to reference resources by guessing names or file paths instead of formulating queries for the semantic search. What seemed at first to be a bug or a flaw in the agent’s instructions turned out to be a subtle hint at how agents behave instinctively.
Building on the content nodes architecture we'd shipped months earlier, we set out to build what our agents were hinting at: tools to navigate a data hierarchy by listing the files in a folder, searching for content by name or opening a certain file.
Identifying the missing primitive
Agents using codebases were constantly trying to 'hack' the semantic search to find specific files by path or filename.
We'd built semantic search to help agents find information based on meaning. But when you need "the TeamOS section of last week's team meeting notes," you're not searching for meaning, you're navigating structure. You know there's a meetings database, you know there are weekly entries, you know where to look. Our agents needed the same capability.
We realized we weren't just building navigation tools. We were creating synthetic filesystems—imposing coherent, navigable structures on data sources that have no filesystem at all.
Crafting a structure to navigate
Notion doesn't have folders, only pages and databases. Slack has channels and threads. Google Drive has its own thing. But our agents needed one consistent way to navigate everything.
As one engineer put it: "We can map a synthetic structure to an actually browsable and searchable one, and nothing blocks us from revamping the content node hierarchy of a connector that does not inherently have one (e.g. Slack) to make the search more powerful."
We weren't limited by how platforms organize data internally. We could create the abstraction that made sense for AI navigation:
- Slack channels become directories that contain files for the threads.
- Notion workspaces become root folders, databases become special directories (both a directory and a table).
- GitHub repositories maintain their natural structure.
- Google and Microsoft spreadsheets become folders of tables.
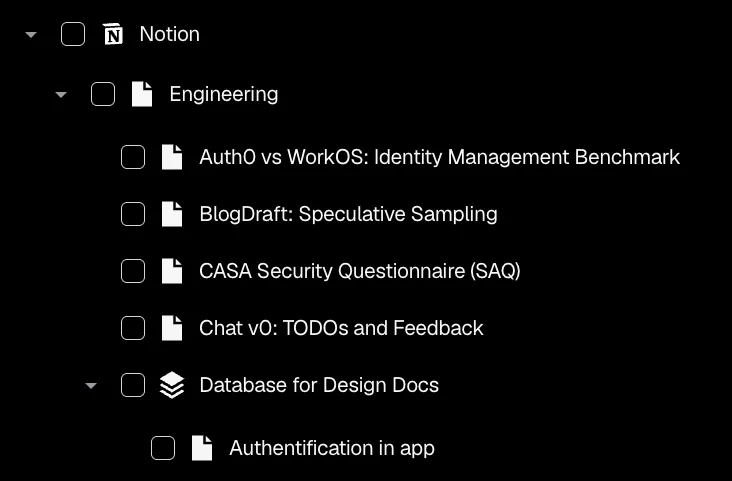
Fortunately, all of this work had already been done in the context of the migration to the so-called content nodes architecture. Only, we had no idea back then that this hierarchy would have a use beyond allowing users to select subsets of their knowledge base in the Agent Builder.
The implementation
We implemented five Unix-inspired commands:
list- Shows folder contents (likels)find- Searches for files by name within hierarchiescat- Reads file contents with paginationsearch- Semantic search within specific subtreeslocate_in_tree- Shows the complete path that leads to the file
Each operates on our synthetic filesystem, treating Notion pages, Slack messages, and Google Drive documents as if they were files or folders in a Unix system. (Unix is a computer operating system from the 1970s that became the foundation for many modern systems like macOS and Linux.).
In fact, everyone relies on the same primitives when looking for files on their computer. File explorers like Finder on Mac are only but an interface on top of these commands; ls is replaced by a visual feedback regarding what you find in a folder after opening it, we are used to searching files by name, and often take a peek at what’s in a file to guess what it is about.
Context window issues
One interesting challenge came with cat. In Unix, it dumps the entire file. But AI agents have context windows, which are hard limits on how much text they can process. A naive implementation would have agents trying to read massive files and immediately failing.
We added limit and offset parameters: the agent chooses to see a certain number of lines starting from a certain line number.
cat: {
nodeId: string,
offset?: number, // Start position
limit?: number, // Max characters
grep?: string // Filter lines
}
This lets agents read documents in chunks, jump to specific sections, and filter content, all without exploding their context windows. This lets agents handle arbitrarily large documents.
Think of this change like a computer with tons of storage space but very little working memory (RAM). Such a computer would struggle to read large files at once and would need to come up with some way to peek at files to guess what their content is about without having to pull them entirely. In that regard, the LLM acts like a program on your computer that must intelligently sample parts of files to grasp what they contain, all while working within strict memory limitations.
Files that are also folders
Traditional filesystems are binary: something is either a file or a folder. Notion broke this assumption—documents can contain other documents, recursively.
We had to reconcile this with the Unix metaphor. A Notion page might be a file you can cat (show its content), but also a directory you can ls (list its children). We fixed this by telling the model whether a given file contains nested items or stands alone, making this information the main criterion for being listable. This dual nature lets agents navigate complex document structures naturally—they can read a page's content, then dive into its sub-pages, all using familiar filesystem commands. Fortunately, in the Unix commands LLMs have seen in their training set, the command itself does not mention whether each argument is a file or a folder; it’s mostly the fact that a certain command is run on a file or folder that tells that. Therefore, listing the children of a file looks legitimate for models syntax-wise.
Two approaches, one system
Here's what happened when we deployed. User asks: "What was in the TeamOS section of the last team weekly's notion doc?".
The agent:
- Uses
findto locate the team weeklies database - Calls
listto see recent entries - Identifies the latest document
- Uses
catwith grep to find the TeamOS section
This structure doesn't exist in Notion's API. We created it to match how humans think about their data.
The interesting part is how agents combine these filesystem tools with semantic search. File system tools don't replace semantic search; they complete it. Navigation helps agents understand the structure and explore systematically. Semantic search finds specific information within that structure. Together, they let agents narrow the scope, then search precisely.
Consider a different workflow. An agent investigating why a feature is broken might:
- Start with semantic
searchacross the entire codebase for error messages or stack traces - Use
locate_in_treeon the results to understand where related files live in the architecture - Navigate to parent directories and use
listto discover related modules and configuration files - Apply focused semantic search within those specific subtrees to understand the broader context
- Finally
catspecific files to examine implementation details
Each command is simple. Together, they let agents navigate organizational knowledge with the same fluency as a Unix expert navigates a filesystem.
We unified both approaches into one toolkit. As our product team described it: "It's search, include, and extract all at once, without having to configure it!" This wasn't just about convenience—it was about recognizing that agents need both capabilities working in concert.
This combination mirrors how humans actually work with information. We don't just search—we browse, we explore adjacent content, we build mental maps of where things live. By giving agents both tools, we enable them to develop similar contextual understanding.
Agents were already trying to do this. They'd attempt semantic searches with path-like queries: "search in /engineering/runbooks for deployment procedures." Now they can actually execute that intent: navigate to the runbooks folder, then search within it. The synthetic filesystem became the scaffolding that made semantic search more efficient, while semantic search still had the ability to quickly go extremely deep and find interesting bits of content scattered across a knowledge base, which can then act as seeds from where the agent has the ability to explore.
Conclusion
The future of work won't be defined solely by how smart AI models become, but by the infrastructure that lets them understand and navigate organizational complexity. Just as Unix provided universal primitives that shaped decades of computing, these navigation tools represent foundational patterns for how AI will interact with company knowledge.
These navigation tools give AI agents a filesystem that doesn't exist on any disk, one that lives in the logical space between disparate data sources. A synthetic filesystem that makes the chaos of organizational data as navigable as a Unix directory tree.
This shift matters because it transforms what agents can do. When agents can navigate structure as fluently as they search for meaning, they move from being sophisticated search engines to becoming true knowledge workers. They develop contextual understanding, discover relationships between information, and tackle complex multi-step tasks that require both broad exploration and deep investigation. Our agents' instinctive reach for these filesystem patterns reveals something broader: as AI capabilities expand, they need richer ways to understand the information landscapes they operate in. The synthetic filesystem lays this groundwork, enabling AI systems that don't just process information but truly comprehend how organizations structure and use their knowledge.
The tools are live now as "Advanced Search" in the Agent Builder. Contact support@dust.tt to enable them for your workspace.