Extract Structured Data from Unstructured Sources with AI


Have you ever wished you could organize all your written knowledge in a structured way? I'm talking about Slack discussions, support tickets, customer feedback... A ton of information gets lost and sits on a server forever.
Today marks the end of an era. At Dust, we worked hard to release a new action your custom agents can perform: Extract data.
This is one of our most remarkable achievements to date because of the ease with which we can now achieve impressive accuracy in structuring things that were previously impossible to classify or structure before the existence of LLMs.
In this article's example, we will aim to gather all of our customer's bug reports and feedback in a structured, clean way from any source.
If you're a reader, read on or head to the Extract Data Documentation. If you prefer the video version, here it is (6m40):
Let's get started: Create a @bugBuster agent that compiles bug reports and feedback.
As a reminder, we're trying to create an agent that will gather all customers bug reports and feedback from different datasources. For the sake of staying concise in this article, we'll only use Slack - but you can plug a lot more sources if needed.
Let's start by Creating a new agent, with these instructions (you can improve them later):

You will receive data from different Slack channels, which are discussions that can include user feedback or bug reports on our product.
Your goal is to summarize the feedback and consolidate it in 2 different sections : bugs and feedback. Bugs should be the first section and are classified as bugs only if the user could not do what they were trying to achieve because the product was broken.
Because the data is coming from different channels, you need to aggregate all the discussions by subject, as any number of customers can be giving feedback or raise awareness about the same bug.
For each bug or feedback, we want to find a title, a short description, the company or companies reporting it and when it was first reported.
The name of the customer is usually a company, and the company name can be in the slack channel title.
In it's Action & Data sources panel, we will choose the Use data sources action, and Extract data method.
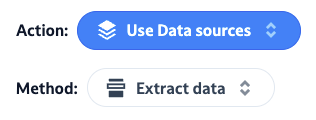
You then simply need to tell your agents which data sources you want to dig in, and for how long in the past.
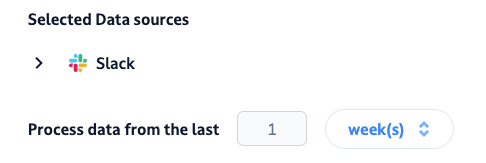
Here, we selected Slack as a data source, and ticked all the channels that we share directly with enterprise customers (but again, you can add any other data source). We believe that running this agent every week is a good way to stay on top of any reported bug or feedback.
The next step is simply to click on that magical button:

This is the structure of the data that Dust has inferred from our agent's prompt. Sounds pretty much exactly like what we're trying to extract:
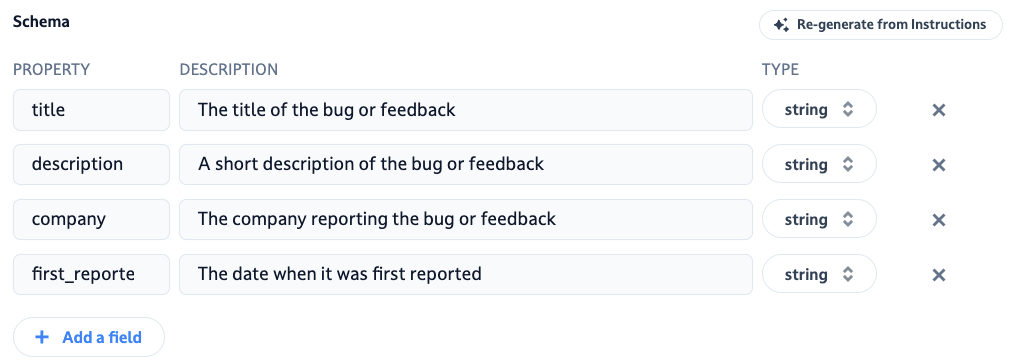
You can tweak that to your needs, of course. But I dont feel like I need to here, as we're receiving all the info we want.
Annnnnd... that's it. We're done.
We just have to name our agent, and use it!
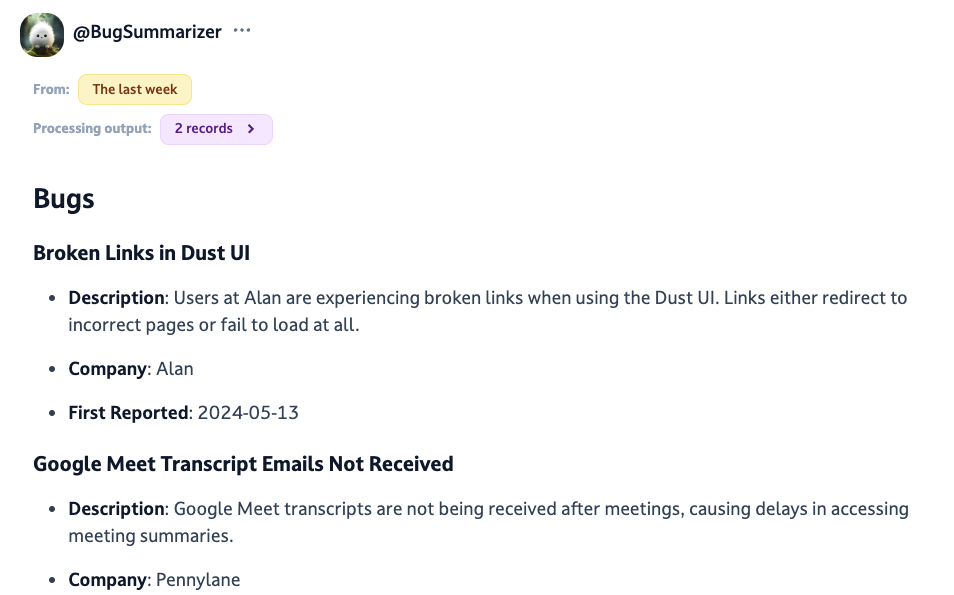
Let see it in action!
Have any questions on how this could help with your specific use cases? Don't hesitate to reach out at team_at_dust.tt.
This is a brand new feature that offers so much to explore.
Exciting!