Dust is better at company data

Word is on the street that for AI agents to be useful at work, they should be plugged to your company data. But when an AI agent provider says it's ‘plugged to your company data’ it actually doesn't mean anything. It's like saying a restaurant should serve food. Sure it should, but there are many ways to do it, and you don't want to end up in the overpriced hastily-unfrozen-meal tourist joint.
What is valuable is agents being able to automatically use the right data to do the things you asked. There is a challenge there: not only can data come from a lot of different company systems (Sharepoint, Google Drive, Slack, Confluence, Intercom, etc.) in high volume, but also, the data gathering method and ingestion algorithm matter a lot, they can make agents' outputs go from useless to excellent—or the other way round.
For instance, when the AI agent generates a report on the latest product feedback, if the data gathering and ingestion isn't done properly:
- it might miss important feedback because customers wrote "love this feature" or "UX needs work" instead of using the word "feedback";
- it might split a long product review right in the middle, putting the problem description in one chunk and the proposed solution in another;
- it might lose the context that feedback from the "Mobile App Discussion" section was specifically about the iOS version;
etc.
Why do we care about how agents gather data
AI agents are limited in the volume of data they can ingest before answering a request. Furthermore, the quality of their output will be worse if there’s a lot of noise in the data they are given—just like humans, who can't read the whole internet before doing something, and who will likely work better if the information presented to them is highly relevant, whereas if the important bits are drowned into noise.
So for cost, time, and efficiency reasons it's better for the agent to narrow down information as well as possible before answering.
This is why search efficiency is particularly important. There are mainly two ways to find useful documents for AI agents: (footnote: referring here to textual content)
- search by keyword, that we all know and use in the search bars of e.g. Google Drive or Microsoft Office;
- search by meaning, a technique based on recent advances in AI, often called "semantic search".
Let's use another example. If you're asking your AI agent to make a summary of discussions on your company's performance in Europe last year, what search & ingest will work?
Keyword search will fail
If the agent uses keyword search, and decides to search for "performance Europe", then the search won't match docs talking about "EU revenue", it won't match docs talking about "ARR in Germany", it won't match docs talking about "Spanish KPIs", etc. because those are not the same words.
You don't want to have to list each different keyword for every information bit related to performance in Europe---and redo that when this time you want the performance in MENA, or basically every time you want to find something new. That would be, like, totes impractical bro.
In addition to that, the results will likely be poisoned by documents that have the right keywords, but are actually irrelevant. For instance, files that talk about the performance of employee X or contractor Y and have "Division: Europe" in their footer or tags. Or documents on the general performance of markets in Europe (but not of your company specifically).
Basic semantic search will fail
Semantic search needs to slice documents in little pieces to work. By default, this slicing doesn't take the document's structure, i.e. its title, sections, subsections, etc., into account (because it's hard to do that well).
So, if in the memo called "Worldwide Company Update" there's a section about Europe after 4 paragraphs, in which the subsection about "Aggregated revenue" comes third, after the section about People, and the section about Products, it won't properly be matched—while it likely contains exactly what you're looking for. "Europe" is in one slice and "Aggregated revenue" in another: none of the slices matches well.
So what will work?
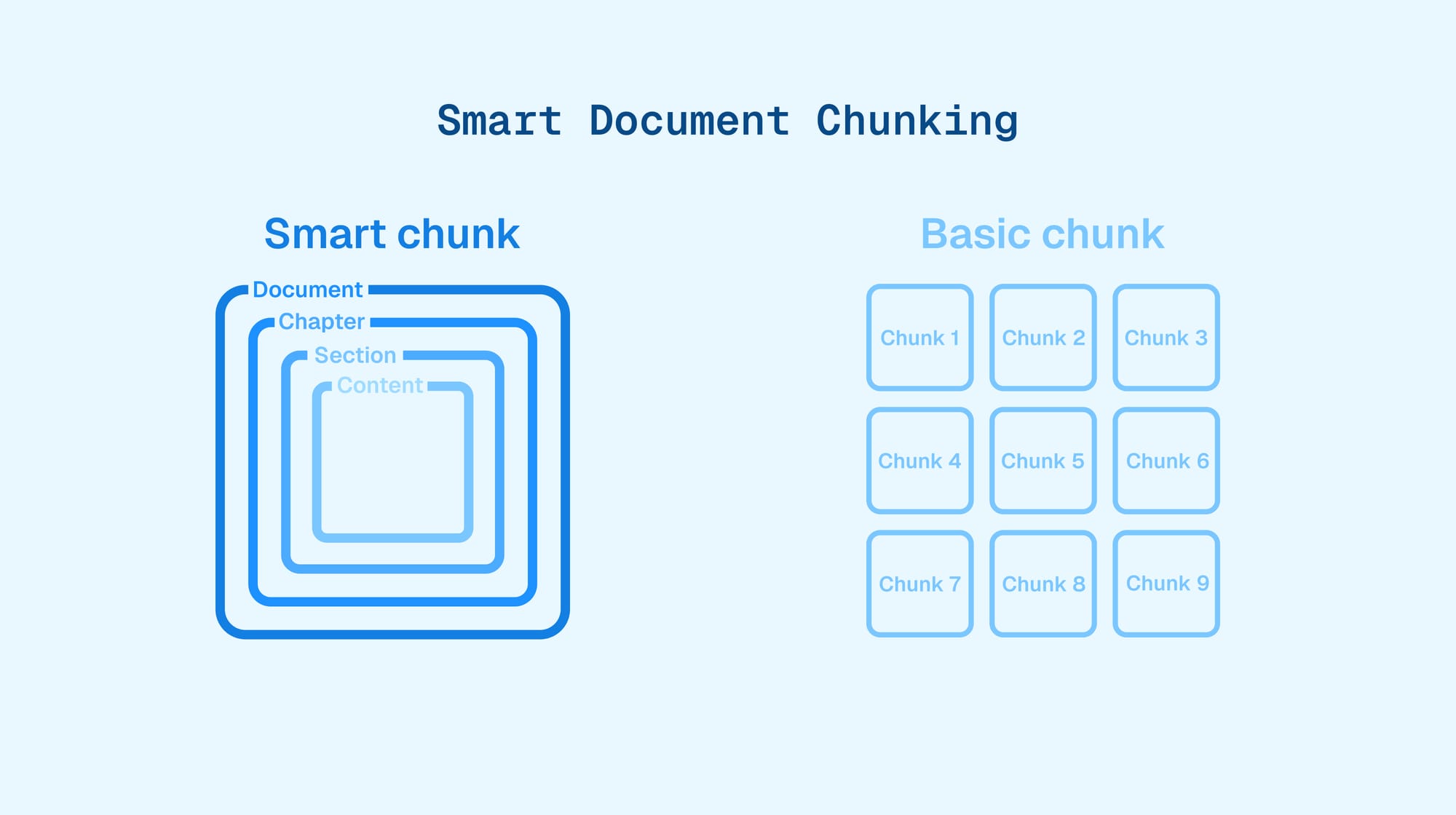
TL;DR: Structure-preserving Balanced chunking¹.
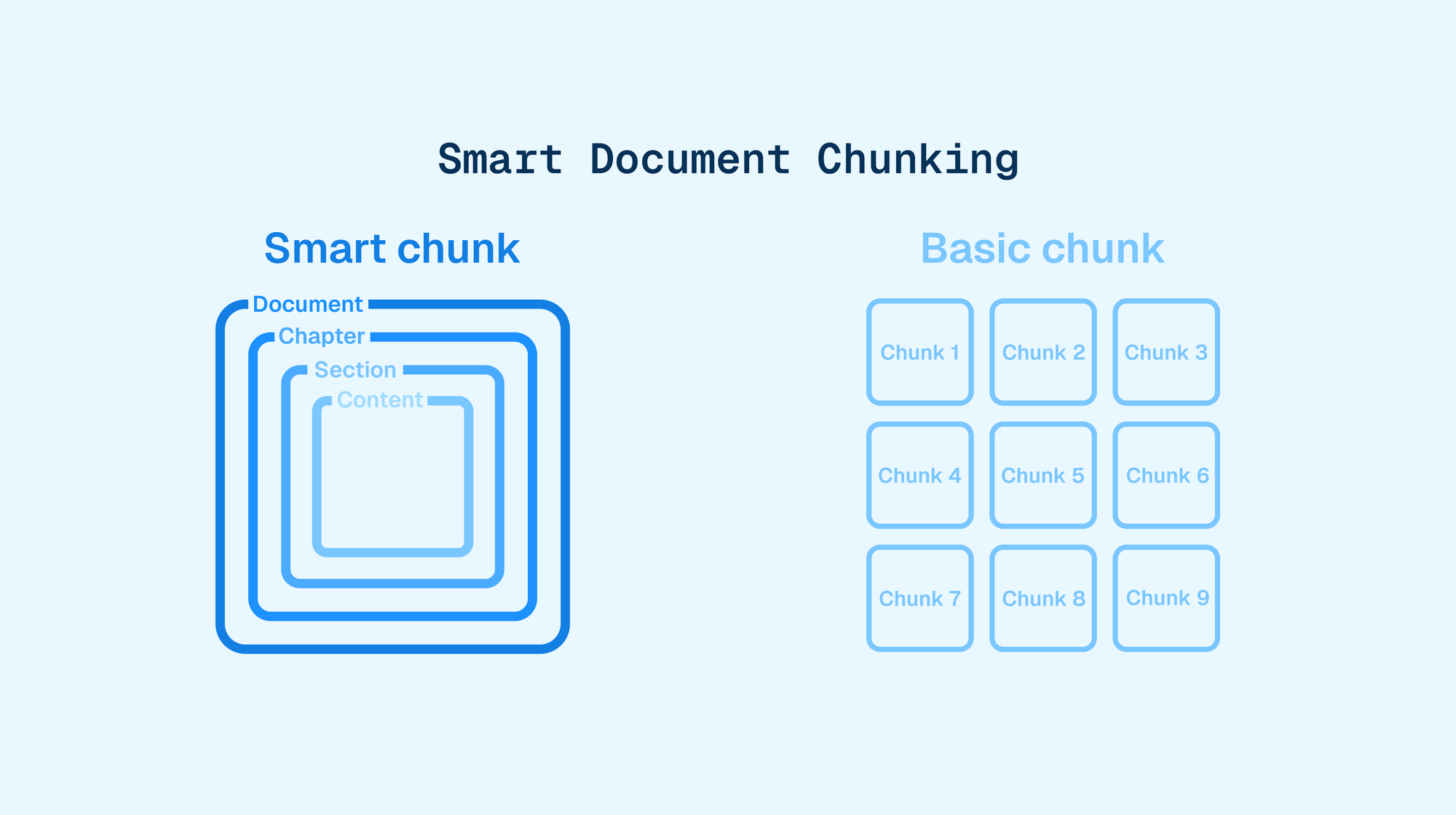
In a few more words: semantic search cuts documents in small slices³ called chunks, then checks which chunks have a similar meaning to the user’s query. To make it work well, you need a subtle algorithm. It must ensure that:
- chunks preserve information about titles, subtitles etc. (the structure)
- all chunks are about the same size, as much as possible (the balance)
- chunks’ sizes should be as close as possible to—while remaining lower than—the maximum size
- unnecessary section splits across chunks, such as widows and orphans, are avoided (the balance in the structure)
- this means, for instance, avoiding that subsection a. and first two sentences of subsection b. are in a given chunk, then the rest of subsection b. is in another
Preserving meaning through document structure
When chunking technical documents, splitting text at arbitrary positions destroys vital context. Our algorithm maintains hierarchical relationships by treating documents as nested sections - imagine chapters in a manual that automatically include their section headers when split. This structural awareness ensures each chunk self-reports its position in the document tree, preventing misinterpretation of isolated content.
We implement this recursively but pragmatically: while repeating headings at every level (e.g., "Chapter 3 > Section 2.A > Subpart iii"), we cap structural metadata at 50% of chunk capacity. This prevents edge cases where over-structured chunks would repeat headings more than content - a critical balance when processing deeply nested technical specifications.
Avoiding context fragmentation
Poor chunking creates "widowed" content - imagine a medical guideline where treatment recommendations get separated from their dosage tables. Our algorithm prevents this through two safeguards: level consistency (only group content from the same section hierarchy) and atomic section handling (keep entire subsections together when possible).
For example, in legal contracts, this ensures definitions stay bound to their operative clauses. A RAG system using basic chunking might miss critical connections - like searching for "termination for cause" but only finding partial clauses without applicable conditions.

Optimizing information density
We maximize chunk sizes to the limits of modern embedding models (typically 512/1024/2048 tokens), driven by two key considerations. Semantically, larger chunks preserve more contextual relationships, crucial for understanding technical nuances. Operationally, fewer chunks reduce vector database load and speed up query processing.
Our token-based approach measures content like LLMs do, avoiding the mismatches of character/word counting. Through dynamic selection flushing, we increase chunk utilization rates - think of it as precision packing for AI context windows.
Overall, the balanced structure-preserving chunking algorithm we devised at Dust does ensure that each piece of data used for semantic search preserves structure information, is as close to the optimal size as possible, and avoids orphans and widows.
For these reasons, in many cases, the difference between professionally executed semantic search and basic semantic search or keyword search, is not just better, it’s binary. One works while the others don't.
Other concerns beyond data ingestion
There's not only search that comes into play for plugging company data to AI agents usefully. There's also, for instance, how often the data is refreshed for the agents.
A good rate should be near real-time (and at no additional cost). It's quite important in practice because otherwise the mental load in using the agent may overcome its usefulness. When a collaborator asks something to an agent, they shouldn't have to remember that Google Drive is synced every day at midnight, so the data from this morning won't be taken into account for the Google Drive part. And Confluence is synced every week, at what time again? so will the agent's answer based on data from Monday on Confluence and today at midnight on Google Drive make sense? 🤯
In that respect, it's more important to be plugged to fresh data than lots of data. That would be a topic for a follow-up post.
[1] Patent pending²
[2] Actually, no. But maybe we should.
[3] While it could technically be possible to try to do semantic search without cutting the document in pieces, it would not work well. Not because of a technology lack, but because meaning gets diffuse in larger text (this would be a topic for another post)