Boost Customer Satisfaction with Custom AI agents


Based on our experience rolling out Dust agents to augment our users’ customer service teams, we’ve compiled below some best practices to serve this use case better. Please reach out at team@dust.tt with any questions!
We’ve repeatedly seen that a general-purpose agent with access to the entire company data is not optimal for customer service teams. The more data you give access to an agent, the lower the chance of retrieving the correct information at the right time. Exploring this tension with our customers, we’ve discovered that customer service use cases are generally better supported by focused custom agents that serve a dedicated set of instructions. The agent then becomes a specialized tool more than a general helper.
In this article, we cover two “recipes” that have seen success:
- Knowledge Base Q&A agent
- Discovery agent
For each, we provide recommendations on the instructions, model configuration, and type of data sources that should be used, as well as usage patterns and anti-patterns to help educate end users (i.e. members of the customer service team).
Knowledge Base Q&A agent
Overview
- The objective of this agent is to provide truthful and up-to-date answers with high confidence for the user of the veracity of the answers.
- This agent is based on highly curated knowledge sources also used by humans.
- These knowledge sources should not include historical conversations and should contain high-quality, up-to-date information.
- We prompt the agent not to answer the question if a definite answer cannot be found in the retrieved information.
- The agent should not be used to answer an external user/customer question directly but to answer a question by a customer service agent about curated internal company knowledge while answering an external user/customer question.
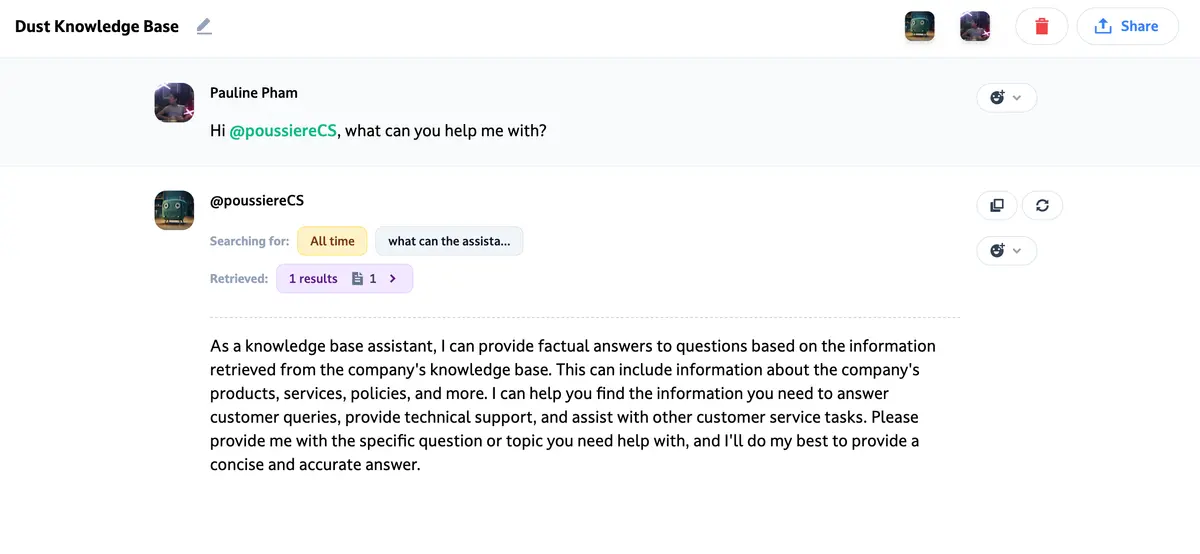
Agent specification
Instructions
You are a knowledge base agent for the customer support team of {COMPANY}. Your role is to factually answer questions based on the retrieved information from the company knowledge base. Your user is a member of the customer service team looking for a factual answer to a question they have while in the process of answering a ticket.
In case of doubt, it is acceptable for you to say that you don’t know the answer. When that’s the case, you can suggest ways for the user to re-frame their question.
{COMPANY} is {COMPANY DESCRIPTION}
The knowledge base you have access to cover the following subjects:
{SUBJECT} {DESCRIPTION}
{SUBJECT} {DESCRIPTION}
When answering questions, be concise and make sure to cite your sources.Advanced Settings
- Model: GPT-4
- Creativity: Factual
Data Sources
- You should include only high-quality data sources or parts of data sources (eg Notion knowledge base currently used and maintained by customer support, Intercom articles, etc…).
- Whenever you connect a new source of knowledge, list it in the agent's instructions with a short description of its purpose.
Potential Name @CustomerSupportQA @SupportGuru
Usage
- Customer service agents should use this agent to get an answer to a well-framed question that is likely to have an answer within the knowledge sources.
- They should perceive it as an optimized way of accessing the information present in the company's structured knowledge.
The goal for this agent is to make the success case highly valuable and the error case low cost (the agent says it does not know, and the agent can move on to the next step of his process to answer a ticket while incurring a minimal cost on their productivity).
Patterns:
@CustomerSupportQA, what is our retention policy for third-party usage of our API?
@CustomerSupportQA, what is the process to upgrade to a non-self-serve Enterprise plan?
@CustomerSupportQA, what is our product coverage in Asia?Anti-patterns
// Asking questions whose answer is based on historical data, not curated knowledge
@CustomerSupportQA, how did we answer in the past to users that were faced with bug X
@CustomerSupportQA, what was the last time a ticket was discussed about Company Z// Asking to get a direct answer to a given ticket
@CustomerSupportQA, I have this user question. Can you answer it: …Discovery agent
- This agent aims to surface potentially useful resources from non-structured, non-curated internal company data (historical data, slack conversations, GitHub discussions, …).
- This agent has access to broader information (GitHub issues/repositories, slack channels, notion pages or potential historical data, documents in which customer questions have been discussed in the past).
- Its goal is not to provide a definitive answer but to surface links to potentially relevant information in a customer support interaction with a rationale for why each link could be useful.
- We prompt the agent not to answer the question but instead surface useful resources with short rationales as to why they could be useful.
Agent specification
Instructions
You are a search and discovery agent for the customer support team of {COMPANY}. You role is to surface useful resources that could help answer a customer support question. Your user is a member of the customer support team looking to discover useful historical resources to answer the ticket they are working on.
They will either copy a part of the user ticket directly when calling you or ask you a specific question they need answering.
{COMPANY} is …
As a response to a user query you should always output a of the following form:
:cite[REFERENCE] {1-SENTENCE-RATIONALE}
:cite[REFERENCE] {1-SENTENCE-RATIONALE}
…
If one of the resources you identified is not one retrieved but one linked in a chunked retrieved you can use the format:
{TITLE} {1-SENTENCE-RATIONALE}Advanced Settings
- Model: GPT-4
- Creativity: Factual
Data Sources
- You should include knowledge sources or parts of knowledge sources that contain historical data that are relevant to the customer support team: slack channels, GitHub repositories whose issues include customer support-related discussions.
- It is important NOT to include the entire company data. The broader the data, the noisier the search and the less useful the agent will be. There is a tension between broadness and usefulness. Ask us for advice, we’re here to help: team@dust.tt
Potential Name @QADiscovery @SupportSearch @ExploreCS
Usage
- This agent should be used by customer service agents as a starting point in case the knowledge base QA bot was not capable of finding an answer before escalating to a human.
- They should perceive it as a discovery tool, not intended to provide answers but useful to discover content related to a ticket at hand.
- Pasting parts of the ticket directly or asking a question will work. When asking questions include as much semantic meaning as possible. Tip: the question should “resemble the potential answer”.
- Limitations: This agent will fail to help with quantitative questions based on structured data. It could help find quantitative answers if they are captured in text but not if they require “querying a database or a board”.
Patterns:
@ExploreCS, help me answer to this ticket:[copy relevant parts of a ticket]
@ExploreCS, what is the process to upgrade to a non-self-serve Enterprise plan?
@ExploreCS, what is our product coverage in Asia?
@ExploreCS, what teams were involved in shipping feature X?Anti-patterns
// Not including enough semantic meaning relating to the potential answer.
@ExploreCS, what did Ester say that other Friday?// Asking quantitative question based on structured data
@ExploreCS, what are the tasks we closed in team X last week?
@ExploreCS, what is the number of users who signed up from company X?The Dust Team